Feed Aggregator
MySQL JMeter Webshop Benchmark
Abstract: In this article we provide a little JMeter WebShop Example Benchmark for MySQL.
For our Advanced MySQL Developer Workshop we have one exercise Benchmarking MySQL with JMeter. For this exercise we are using the FoodMart-2.0
[1
] Schema and simulating a simple WebShop Transaction:
- Logging in
- Put some articles into the basket
- Buy the articles
- Log out
I found it pretty hard to find good and detailed examples how to do this with JMeter and I wasted a lot of time searching and figuring out how it works.
So I decided to provide my example (webshop_benchmark.tgz) with the hope that you can safe some time looking at it and using it as base for your own Benchmarks.
I am really wondering if JMeter is used a lot at all in combination with database Benchmarks because otherwise I would have expected much more examples and information.
Possibly JMeter is used to call the Java methods directly?
Please let me know your findings and suggestions how to improve it so I can learn some more things about JMeter.
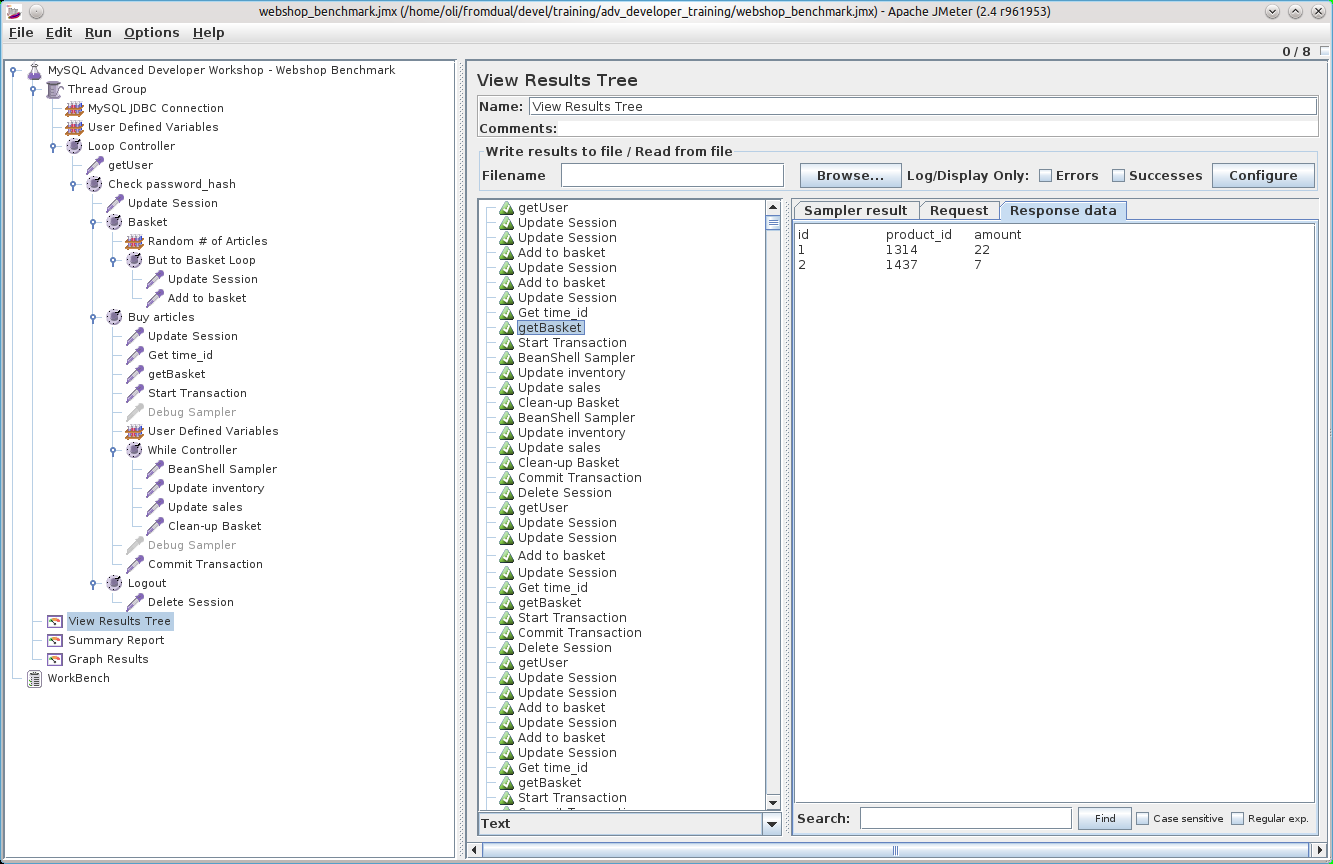
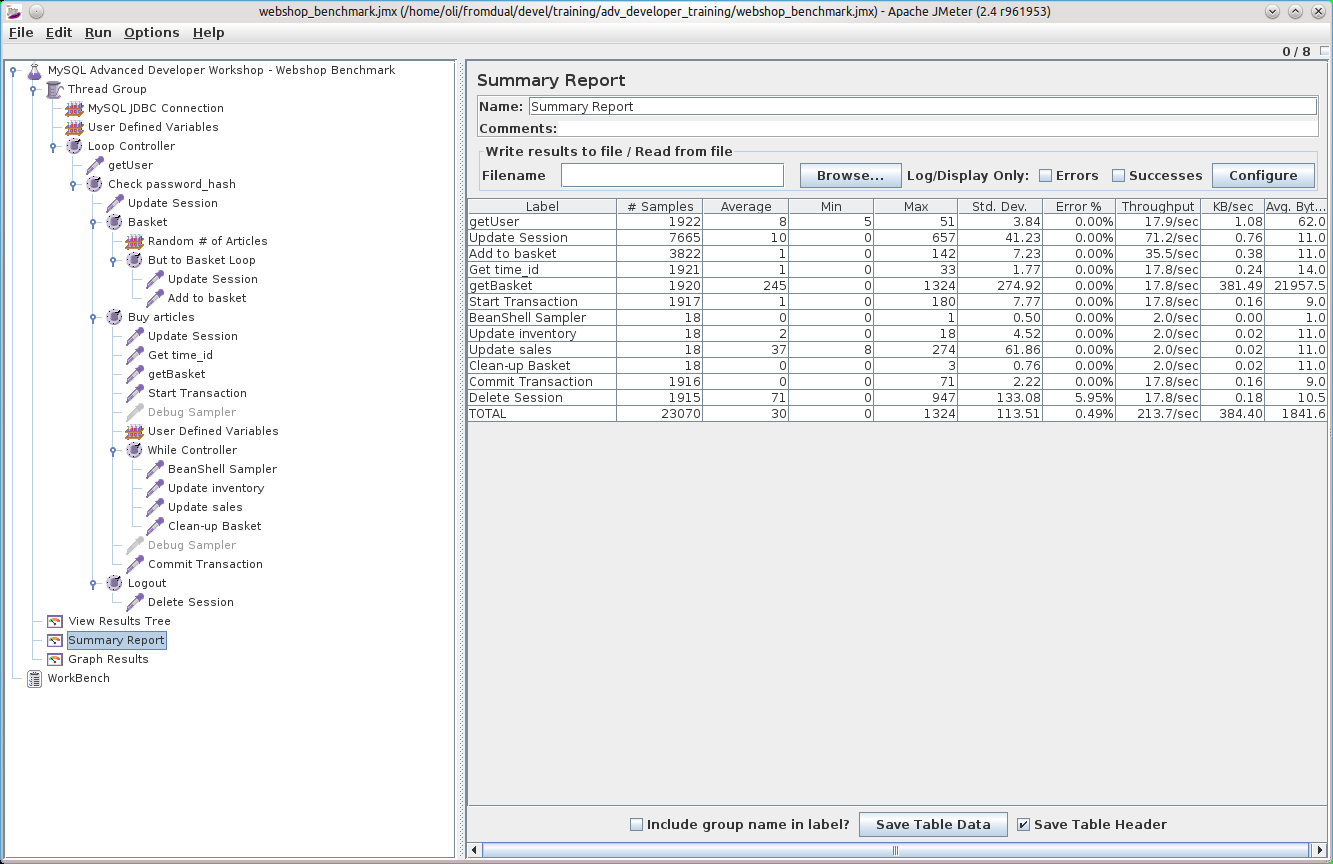
Taxonomy upgrade extras: english, benchmark, performance, jmeter,
Categories:
To zip, or not to zip, that is the question
Abstract: In this article we have a look at the compression options of common zipping tools and its impact on the size of the compressed files and the compression time. Further we look at the new parallel zip tools which make use of several cores.
Start with a backup first
From time to time I get into the situation where I have to compress some database files. This happens usually when I have to do some recovery work on customers systems. Our rule number 1 before starting with a recovery is: Do a file system backup first before starting!
This is sometimes difficult to explain to a customer especially if it is a critical system and time runs (and money is lost).
It happens as well that there is not enough space available on the disks (in an ideal world I like to have a bit more than 50% of free space on the disks). Up to now I have used the best compression method. This comes to the cost of performance.
An other reason to use compression is to increases I/O throughput when the I/O system is the limiting factor …
Taxonomy upgrade extras: english, backup, recovery, compress, zip, tar,
Categories:
I, too, prefer NULL, but...
If you’re using NULL to represent “anytime in the past/future” for DATETIME, that means that you need “special handling” for what would otherwise be simple inequalities.
For examples, I often store validity ranges with DATETIME; but that means I can no longer query if “valid_from > ‘2011-07-22 00:00:00’”, since that will through out any ( valid_from = NULL ) records. That’s not what I mean here – if the valid_from is NULL, that means they are always valid.
So in these particular cases, I prefer to use ‘0’ and ‘9999-12-31’ as special values so that index usage is correct and WHERE clauses are simplified.
But otherwise, yes, if NULL means “unknown”, as opposed to “special”, I entirely agree.
Taxonomy upgrade extras:
Categories:
Henrik - your conclusions are
Henrik - your conclusions are too strong. If you want performant code then SQL, PL/SQL, whatever might be a bad choice. Or it might be a good choice. This just shows that that MySQL stored procedures are slower than PL/SQL and insert triggers slow down an insert. This also shows that PHP is slow and that hasn’t prevented successful deployments of it. There are many other things to consider when deciding whether to use a stored procedure or do it on the client side.
Taxonomy upgrade extras:
Categories:
I think Oli makes exactly
I think Oli makes exactly that point here. I think it’s correct to say that if you want performant code for some computation, then SQL is a bad choice, even PL/SQL. Whether MySQL or Oracle is “less bad” is kind of uninteresting, I agree with you MySQL performance is acceptable if it’s within 2x from Oracle.
The point with the given test here (which I didn’t understand at first) is that using a trigger (or other stored procedure) you can save network roundtrips. In this case it turns out that writing your log table from a trigger is faster than writing 2 rows from sysbench.
Taxonomy upgrade extras:
Categories:
How good is MySQL INSERT TRIGGER performance
Abstract: In this article we discuss how big is the performance impact of MySQL TRIGGERs compared to application side logging (with INSERT) into a MySQL table.
What was in my mind from the past
A while ago when MySQL released its Stored Language features in v5.0 I have seen a book
[1
] about this topic. In this book was a performance comparison between different implementations of computational tasks, one was done in MySQL Stored Language. The result was, that MySQL Stored Language feature sucks also performance wise.
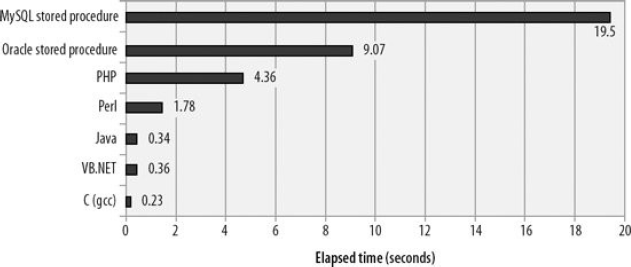
Now a customer of us wanted to use TRIGGERs to log/track some database activity. Because I am not a big fan of Stored Languages at all and because I had this performance comparison in mind I was not convinced if this is a good idea but I did not know it for sure and wanted to give an answer based on facts.
The Test
To find out how much the performance impact of MySQL TRIGGERs really is we made some little benchmarks. For this benchmark we used the following log table:
CREATE TABLE log (
`id` …Taxonomy upgrade extras: english, mysql, benchmark, performance, trigger, innodb, myisam, insert, pl/sql, sql/psm,
Categories:
is it really that bad?
I don’t think that 2X slower than Oracle sucks. Oracle has put a lot of resources into making PL/SQL fast. PHP results aren’t very good on this test – only 2X faster than Oracle and 4X faster than MySQL.
Taxonomy upgrade extras:
Categories:
ER-Diagram of the InnoDB Data Dictionary
With the new MySQL 5.6 release there are some more InnoDB Data Dictionary Tables in the INFORMATION_SCHEMA:
New with MySQL 5.5 are:
| INNODB_CMP |
| INNODB_CMP_RESET |
| INNODB_CMPMEM |
| INNODB_CMPMEM_RESET |
| INNODB_TRX |
| INNODB_LOCK_WAITS |
| INNODB_LOCKS |
New with MySQL 5.6 are:
| INNODB_BUFFER_PAGE |
| INNODB_BUFFER_PAGE_LRU |
| INNODB_BUFFER_POOL_STATS |
| INNODB_FT_CONFIG |
| INNODB_FT_DELETED |
| INNODB_FT_DEFAULT_STOPWORD |
| INNODB_FT_INDEX_CACHE |
| INNODB_FT_BEING_DELETED |
| INNODB_FT_INDEX_TABLE |
| INNODB_FT_INSERTED |
| INNODB_METRICS |
| INNODB_SYS_COLUMNS |
| INNODB_SYS_FIELDS |
| INNODB_SYS_FOREIGN |
| INNODB_SYS_FOREIGN_COLS |
| INNODB_SYS_INDEXES |
| INNODB_SYS_TABLES |
| INNODB_SYS_TABLESTATS |
The INNODB_SYS tables where already available before but not accessible via SQL. You could see them by enabling the InnoDB Table Monitor.
To get a rough overview how they are related to each other we have reverse engineered the ER Diagram of the InnoDB Data Dictionary. Please let us know when you see any error or if something is …
Taxonomy upgrade extras: english, innodb, data dictionary, er-diagram,
Categories:
Corresponding I_S table for Percona Server
Percona Server has had a buffer pool pages I_S table for a while, based on an earlier patch by Jeremy Cole or Eric Bergen, I think. However, I suspect that the Oracle implementation is likely to be safer. Some of the Percona I_S tables dealing with InnoDB internal information have had bugs, and I have become reluctant to use them on production systems. I am glad to see InnoDB providing their own implementation. Here is a link to the list of additional I_S tables provided in Percona Server: http://www.percona.com/docs/wiki/percona-server:features:indexes:index_info_schema_tables
Taxonomy upgrade extras:
Categories:
Buffer pool dump/preload now implemented in InnoDB
Interesting approach, thanks for sharing this hint! However, the latest 5.6 release may have already solved this issue: InnoDB now supports dumping and loading the buffer pool automatically on shutdown and startup: http://blogs.innodb.com/wp/2011/07/shortened-warm-up-times-with-a-preloaded-innodb-buffer-pool/
Taxonomy upgrade extras:
Categories:
generally agree
I do generally agree with the “Conclusion” mentioned at the end of this entry. It will be a topic of different post to discuss and convince people to normalize data if you see too many NULLable columns in the database.
@Stephane This is how nulls are treated by design. For e.g. you may claim that the count of * and count of city should be equal which is not in case of NULL.
mysql> select count(), count(city) from t; +———-+————-+ | count() | count(city) | +———-+————-+ | 1 | 0 | +———-+————-+ 1 row in set (0.00 sec)
Taxonomy upgrade extras:
Categories:
restore buffer pool
Hi Partha Dutta,
What you are describing is mentioned in Literature reference [3].
Taxonomy upgrade extras:
Categories:
"Similar" options available in Percona Server
There is a similar option available in Percona Server (I don’t recall the exact version, but its in the newer 5.1 build) called innodb_auto_lru_dump. Setting this option will dump the innodb LRU queue to disk at specified intervals (innodb_auto_lru_dump=X, where X is the interval in seconds). On server startup, this file will be read, and the corresponding pages referenced will be loaded into the buffer pool.
Taxonomy upgrade extras:
Categories:
Shinguz, thanks a lot for
Shinguz, thanks a lot for your detailed reply. I’d decided to avoid relying on indexing nulls even if MySQL supported it, as insurance against future database switch. But you took the time to test and even publish your results. Highly appreciated!
Taxonomy upgrade extras:
Categories:
Warming up the InnoDB Buffer Pool during start-up
Abstract: Heating up the InnoDB Buffer Pool during the MySQL instance startup should significantly improve InnoDB Performance in the beginning of the life of the Instance. This is achieved by sequential scans of the needed data instead of random I/O reads which would happen when we just let the system work it out by itself.
How to find the database objects which can be loaded during MySQL start-up and how to load them automatically is described in this article.
New Table in the INFORMATION_SCHEMA
Some of my colleagues have already described methods on how to heat up a Slave after its startup.
[1, 2, 3
]
With the Release v5.6 of MySQL there is a new table in the INFORMATION_SCHEMA called INNODB_BUFFER_PAGE. This table contains the information about all pages currently located in the InnoDB Buffer Pool.
A rough overview over the InnoDB Buffer Pool you can get with the following statement:
SHOW GLOBAL STATUS LIKE 'innodb_buffer_pool_pages_%';
+----------------------------------+--------+
| Variable_name …Taxonomy upgrade extras: english, innodb, buffer pool, warm-up, start-up,
Categories:
Different opinions
Some people did not agree with my statements or had some questions…
A search using col_name IS NULL employs indexes if col_name is indexed. [1]
Some experiments on a table with a few (= 4) NULL values:
EXPLAIN SELECT * FROM t2 WHERE dt IS NULL; +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+ | 1 | SIMPLE | t2 | ref | dt | dt | 9 | const | 4 | Using where | +----+-------------+-------+------+---------------+------+---------+-------+------+-------------+
EXPLAIN SELECT * FROM t2 WHERE dt IS NULL OR dt <= '2011-07-16 21:02:00'; +----+-------------+-------+-------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | …
Taxonomy upgrade extras:
Categories:
Using NULL values is
Using NULL values is dangerous because it can lead to incorrect results (or at least unexpected results).
Take the following table:
CREATE TABLE t (
id int(11) NOT NULL DEFAULT 0,
city varchar(10) DEFAULT NULL
);
The following query is expected to return all the rows in the table:
SELECT * FROM t WHERE city=city;
That’s true if the city is not NULL but not if the city is NULL:
mysql> INSERT INTO t (id,city) VALUES (1,‘XXX’);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t WHERE city=city;
+—-+——+
| id | city |
+—-+——+
| 1 | XXX |
+—-+——+
mysql> UPDATE t SET city=NULL WHERE id=1;
mysql> SELECT * FROM t WHERE city=city;
Empty set (0.00 sec)
What’s the problem? MySQL returns in both cases a result that is correct in mathematical logic but the introduction of NULLs changes the kind of logic that applies (3-valued logic instead of 2-valued logic). Unfortunately in the real world, you always think with the …
Taxonomy upgrade extras:
Categories:
I have seen this issue on
I have seen this issue on physical servers as well. sync_binlog can help to avoid the problems.
Taxonomy upgrade extras:
Categories:
Using NULL as default values
Abstract:
It is common practice in MySQL table design that fields are declared as NOT NULL but some non-sense DEFAULT values are specified for unknown field contents. In this article we show why this behavior is non optimal an why you should better declare a field to allow NULL values and use NULL values instead of some dummy values.
What we can see often out in the field
Recently we had a discussion with a customer if it makes more sense to store a default value or NULL in InnoDB tables when we do not know the value of the field yet. About this 8 byte DATETIME field we were discussing:
CREATE TABLE test (
...
, dt DATETIME NOT NULL DEFAULT '0000-00-00 00:00:00'
...
The customer mentioned, that he is mostly storing nothing in this field which in fact results in '0000-00-00 00:00:00' occupying 8 bytes.
This is a situation which happens very often in applications but is ignored or not properly designed. But the MySQL documentation clearly states what are the facts
[1
].
Showing the situation by example
To …
Taxonomy upgrade extras: english, table, default, null, design,
Categories:
Hi, Using date values like
Hi,
Using date values like ‘0000-00-00 00:00:00’ is really terrible, but what about magic non-null values for indexing purposes?
I’ve heard/read that Oracle indexes ignore null values. Example: “where bla is null” would not use index defined on bla. I wonder about MySQL.
If MySQL indexing indeed ignores null values, and you need to track missing information in a big table, you may be better off using some magic non-null value (not elegant, I agree).
Taxonomy upgrade extras:
Categories:
