Feed Aggregator
FromDual DBA on Demand
What you get
With this service you get your regular DBA work done. The difference to our Remote-DBA Service is that our specialist come on-site to your location.
- You get our MySQL DBA working for you on-site.
- You can buy a certain amount of days of DBA work to be performed: The minimum amount is 5 consecutive days.
- According to your business needs your standard database operation work is done on-site by our MySQL DBA’s. This includes for example:
- Setup and installation of your MySQL database servers.
- MySQL Upgrades.
- Database migration.
- Move your services from one machine to an other.
- Extract, Transform and Load (ETL) of your data.
- Query and report creation: So your reports deliver the data they should
- Query tuning: To get best time from your hardware.
- Backup and Restore Testing.
- Load tests and benchmarking
- Configuration and configuration tuning.
- Failover and other system testing.
- This work has to be coordinated and agreed with the Remote DBA team.
Why this product is interesting for you
- You need a …
Taxonomy upgrade extras: dba, remote-dba,
Categories:
Remote-DBA Services for MariaDB and MySQL
Our remote-DBA services are as flexible as our customers are different. We care about your mandates if they are related to MariaDB, MySQL or Galera Cluster. We also can support you in the database surroundings (Linux, Load Balancer, High-Availability). You purchase a 10 hour Service package and you can use it on demand during one year.
How our customers use their FromDual remote-DBA services
Our customers use their FromDual remote-DBA services in many different ways:
- A popular way using our services is to get support via email in case of troubles.
- But mostly we connect in a video conference to discuss and solve problems together.
- A first contact comprises often a system analysis and a database configuration check.
- Our customers also like our expertise in performance troubleshooting, the analysis of resource consumption as well as in SQL query tuning.
- Also in crash analysis and locking problems we can support you.
- Other customers let us review their systems on a regular base and let us do maintenance work on …
Taxonomy upgrade extras: operations, dba, remote-dba,
Categories:
MySQL Database Health Check
What you get
With our FromDual Database Health Check Service for MySQL and MariaDB you get your basic regular DBA work done:
- We check the mission critical information of your databases:
- if your database is running smoothly.
- if your servers have enough free disk space.
- if your backup is done.
- if your MySQL Cluster is up and running and has enough free memory.
- if your replication is up and running and if it is lagging.
- if your security rules are met.
- if your DRBD and Heartbeat set-up is working properly.
- We do a Database Health Check.
- We gather the server metrics for long term trends and capacity planning.
- We gather the database metrics for long term trends and capacity planning.
- We run a monitoring solution for you if wanted.
- The work is performed once a week or once a month and you get a report of the outcome.
- Warnings/Issues are risen when something is found (per email and on our customer web-site).
Why this service is interesting for you
- You want to outsource your MySQL database operations to a …
Taxonomy upgrade extras: health check,
Categories:
PrimeBase Technologies and FromDual form a Service-Cooperation for MySQL products
From the Cooperation of these two companies arises the biggest independent service provider for MySQL and MariaDB in Europe.
Hamburg, Uster – February 28, 2011 - The Hamburg based PrimeBase Technologies and the near Zürich located FromDual are forming a Cooperation for MySQL products and services, starting March 1st, 2011.
This Cooperation enables both companies to offer a complete set of services for all MySQL and MariaDB customers.
The customers of both parties now have he possibility to demand a 24x7 support service from their provider.
Companies, which use MySQL, often do not have the capability to operate the product themselves, because they do not have sufficiently trained MySQL staff.
The Remote-DBA offer meets exactly this need: Customers then have the possibility to let their databases be operated by a MySQL specialist.
In addition, the set of services offers MySQL Health Checks on a regular basis or an Emergency intervention in case of an incident.
The whole package is built modularly and …
Taxonomy upgrade extras: english, mysql, support, primebase, remote-dba, cooperation, product, service, mysql support,
Categories:
FromDual All (En)
FromDual InfoFeed (En)
Zabbix vs Nagios?
Hi
On your download page you have both this Zabbix based performance monitor, and the Nagios plugins. Since I’ve used neither, it would be interesting to read a separate blog post comparing the two.
Also, you say this is free of charge and offered under the GPL. Does this now include also the InnoDB monitoring, or just MySQL Server without InnoDB?
Taxonomy upgrade extras:
Categories:
FromDual releases new version of its MySQL Performance Monitor
FromDual releases its new version v0.5 of its MySQL Performance Monitor working with Zabbix.
What has changed so far in this release:
- Recommended Location has changed to /usr/local
- FromDual agent log files are rotated now.
- There are now 2 different packages: One for the Agent and one for the Templates.
- Some of the graphs were improved.
- Missing status and system variable information were added and some were fixed.
- Verbosity of logging information was adjusted.
- A module for monitoring additional informations for Linux servers was added.
- Agent caches now the data if it has no access to server. This gives the possibility to run the agent without an installed Zabbix Server and load the data later on off-site.
- Start/stop scripts for running Zabbix agent and server under the mysql user were added.
- Status information for the Aria Storage Engine were added.
The MySQL Performance Monitor is free of costs and the modules are offered under GPL.
You can get it from our download page.
If you find some problems or have …
Taxonomy upgrade extras: mysql, performance, enterprise monitor, monitor, performance monitoring, maas,
Categories:
FromDual All (En)
FromDual InfoFeed (En)
MySQL Restore and Recovery methods
Backup is for sissies! Let’s have a look what we can do when we are not a sissy…
First of all: Your life is much easier when you have a proper backup process implemented and verified the restore procedure of your MySQL database.
But what if you have no backup in place and did a DROP TABLE. What shall we do?
We assume our data we just dropped are located on the following device:
# export IMAGE=/dev/hda1
First of all, power off your server. This avoids that the operating system writes data down to disk and overwrites your table you just dropped.
If power off is not possible, try to unmount the file system where the dropped table resides:
# umount -f /mnt/data
If you cannot unmount your disk because somebody or something is sitting on it try to find out who it is:
# lsof /mnt
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 31638 oli cwd DIR 7,0 1024 2 /mnt
When you perform a unmount all the blocks belonging to this file system are flushed to the disk first. So you …
Taxonomy upgrade extras: backup, restore, recovery,
Categories:
channel_failover.pl v0.02
Starting and stopping, status and failover is possible now. Script basically works but should be made a bit more sophisticated still…
Let me know your findings and wishes.
Taxonomy upgrade extras:
Categories:
Closing Circle again and channel_failover script
One thing I forgot to mention: We lost Cluster B. So we rebuilt Cluster B from Cluster A.
Then we set-up channel ch1 from Cluster A to B. This worked fine. When we wanted to set-up Channel ch3 from Cluster B to A we got troubles starting the Slave.
We finally managed to start the Slave when we truncated the ndb_apply_status table. In the documentation is also something mentioned that a RESET SLAVE should work.
And travelling back from a customer I found some time to write a script to show the status of my channels. It is written in Perl. Up to now it can show the status and stop a channel but not more. And it is pretty alpha status still! So use with care.
shell> ./channel_failover.pl status
Status for all channel groups and channels:
Channel group: channel_group_1
IO_thread : Yes - OK
SQL_thread: Yes - OK
Channel ch1 (M: master1, S: slave3) - up
IO_thread : No - OK
SQL_thread: No - OK
Channel ch2 (M: master2, S: slave4) - down
Channel group: channel_group_2 …Taxonomy upgrade extras:
Categories:
auto_increment_increment / auto_increment_offset
Hi Krishna,
I got you and fully agree with you!
Best regards, Oli
Taxonomy upgrade extras:
Categories:
Cluster Circular Replication
Hi Oli,
By mistake i mention log_slave_updates. Actually, i was talking about auto_increment_increment and auto_increment_offset needs to be setup carefully, in order to avoid duplicate key errors on primary key.
Regards, Krishna
Taxonomy upgrade extras:
Categories:
Query and traffic
Hello Ky,
Yes. You got me right! I meant the query on ndb_binlog_index.
With no traffic I mean NO DML statements (INSERT, UPDATE, DELETE, etc.) on that Cluster.
Thanks for asking and clearing this up!
Regards, Oli
Taxonomy upgrade extras:
Categories:
Careful using log_slave_updates
Hi Krishna,
Why do you think we should be carful using log_slave_updates in circular replication set-up’s?
Regards, Oli
Taxonomy upgrade extras:
Categories:
Cluster Circular Replication
Thanks, for such an informative post. It’s a new and interesting HA post. Even, i believe we should be very careful in using log_slave_updates in circular replication setup.
Taxonomy upgrade extras:
Categories:
Recommend channel-failover procedure
Thanks for the post, it is informative. Just have a few quick questions:
Quote: “If you have no traffic this query returns an empty result set”, which query do you mean?
Do you mean the query on master2: “SELECT SUBSTRING_INDEX(File, ‘/’, -1) AS master_log_file”?
Does no traffic mean no active queries to that cluster?
Cheers, Ky
Taxonomy upgrade extras:
Categories:
MySQL Cluster - Cluster circular replication with 2 replication channels
A few days ago I had to deal with MySQL Cluster replication. I did not do this for a while so I was prepared to expect some interesting surprises once again.
For those who MySQL Cluster - Cluster circular replication is the daily business they may skip this article. For all the others they possibly can profit from our learnings.
I am talking about the following MySQL Cluster set-up:

More detailed information about such set-ups you can find in the MySQL Cluster documentation.
Situations that lead to a channel failover
What are the problems with MySQL Cluster that lead to a channel failover:
- MySQL master can loose connection to the MySQL Cluster (lost_event, gap).
- MySQL master cannot catch up with the load of the MySQL Cluster and thus gets a lost event (gap). I am really wondering about the argument in the documentation
[ 1
], that in such a case we can do a channel failover. Because when Master 1 cannot catch up with the load, why should then Master 2 be capable to do it…?).
What a gap (lost_event) …
Taxonomy upgrade extras: english, replication, mysql cluster, channel, failover, circular,
Categories:
Thanks, I appreciate the
Thanks, I appreciate the effort you are taking to find the truth. -Bradley
Taxonomy upgrade extras:
Categories:
Same test for InnoDB
I forgot to mention in the main post that I did these tests with 5.1.50.
Settings for MyISAM this time:
key_buffer_size = 8M sort_buffer_size = 2M read_buffer_size = 128k myisam_sort_buffer_size = 8M
Settings for InnoDB:
# plugin not built-in innodb_file_per_table = 1 innodb_log_file_size = 128m innodb_buffer_pool_size = 384m innodb-flush_log_at_trx_commit = 0 innodb_log_files_in_group = 3 innodb_support_xa = 0
InnoDB table WITHOUT explicit PK and WITH explicit PK:
INDEX: name GEN_CLUST_INDEX, id 0 353, fields 0/12, uniq 1, type 1 FIELDS: DB_ROW_ID DB_TRX_ID DB_ROLL_PTR id f1 f2 f3 f4 f5 f6 f7 f8 INDEX: name PRIMARY, id 0 356, fields 1/11, uniq 1, type 3 FIELDS: id DB_TRX_ID DB_ROLL_PTR f1 f2 f3 f4 f5 f6 f7 f8
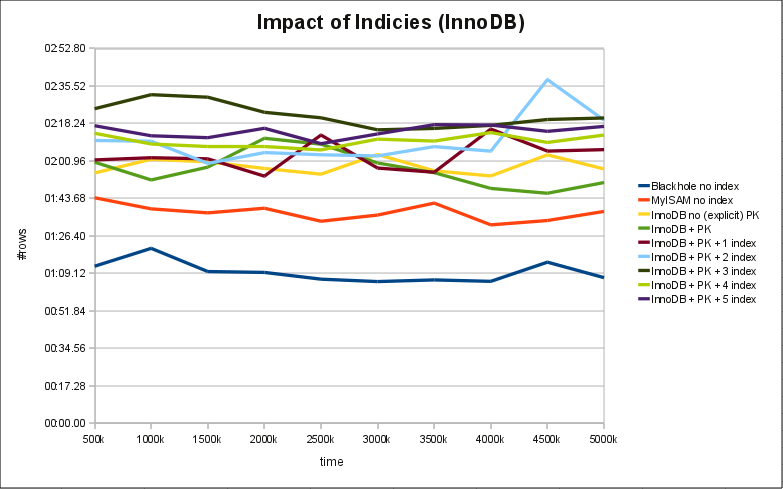
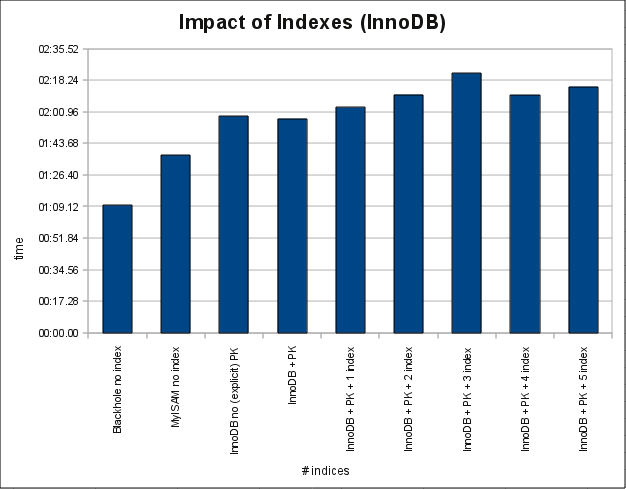
It seems indeed, that InnoDB has a less linear overhead than MyISAM (at least in my test) as long as the data can be kept in Memory. An thus it seems to perform slightly better in the described scenario when we …
Taxonomy upgrade extras:
Categories:
I didn't mean to be flaming,
I didn’t mean to be flaming, I’m sorry if it seemed that way. And I apologize for not noticing that the response to my comment wasn’t from the original author.
I guess I got a different message from the original posting. The original posting observed that indexes cost something. But what’s the point of that observation? The point is to do something to your database to fix the slowness. The original posting implied that dropping some indexes would be one fix to the problem. The chart says fewer indexes means higher performance. So far, so good.
However, there are other things you could do. For example, switch to InnoDB or TokuDB. (There may be other approaches such as using some NoSQL solution, but let’s put those aside for now.)
I guess I misread the original posting. Upon re-reading, it seems like the data in the original posting doesn’t look so bad. After all, inserting 500K rows in 3 minutes instead of 90 seconds to get 5 indexes doesn’t seem so bad. …
Taxonomy upgrade extras:
Categories:
hrm
Let me summarize something. You don’t disagree the cost of maintaining indexes as this blog describes. You are not disagreeing there are “some” costs for innodb either. So there is a flame MyIsam vs. InnoDb left. Which is imho not intended (at least from the author). Btw: Im not working for fromdual, so I don’t give a ***** what they do. If you want to read my homepage just click on my name;)
Taxonomy upgrade extras:
Categories:
