You are here
To zip, or not to zip, that is the question
Mon, 2011-08-08 11:12 — Shinguz
Abstract: In this article we have a look at the compression options of common zipping tools and its impact on the size of the compressed files and the compression time. Further we look at the new parallel zip tools which make use of several cores.
Start with a backup first
From time to time I get into the situation where I have to compress some database files. This happens usually when I have to do some recovery work on customers systems. Our rule number 1 before starting with a recovery is: Do a file system backup first before starting!
This is sometimes difficult to explain to a customer especially if it is a critical system and time runs (and money is lost).
It happens as well that there is not enough space available on the disks (in an ideal world I like to have a bit more than 50% of free space on the disks). Up to now I have used the best compression method. This comes to the cost of performance.
An other reason to use compression is to increases I/O throughput when the I/O system is the limiting factor (bottleneck).
Recently I was pretty short in time but not that short on disk space. So after a while running bzip2 -9 I killed the compression job and started it again with a faster method but less compression.
Which is the best compression method?
After we successfully have recovered the customers system I really wondered which would be the best compression tool and its options so I did some investigations with gzip and bzip2. In these tests I did not consider the compress tool which was used in the old times on unixoide systems nor did I look at zip or 7z which is less common on Linux and has some inconvenient Windows style syntax.
Further I was very interested in the new parallel compression features of gzip and bzip2 which should make use of several cores on modern multi-core systems. This is especially helpful because compressing is mostly CPU limited and on multi-core machines the other cores are often idling.
For testing I tared the 2 InnoDB log files together with the ibdata file which resulted in one big 2.5 Gbyte file. The following tests were done with this file. I hope the results are somehow representative for most MySQL compression problems.
I used a Machine with 8 virtual Intel i7 870 cores (4 real cores) and 2.93 Ghz and 16 GByte of RAM. So the whole test should be completely Memory/CPU bound.
The Test
For testing I used the following script:
#!/bin/bash for i in `seq 1 9` ; do echo gzip -$i test.ibd time gzip -$i test.ibd ls -la test.ibd.gz gzip -d test.ibd.gz done for i in `seq 1 9` ; do echo bzip2 -$i test.ibd time bzip2 -$i test.ibd ls -la test.ibd.bz2 bzip2 -d test.ibd.bz2 done for i in `seq 1 8` ; do echo pigz -p$i test.ibd time pigz -p$i test.ibd ls -la test.ibd.gz pigz -d test.ibd.gz done for i in `seq 1 8` ; do echo pbzip2 -p$i test.ibd time pbzip2 -p$i test.ibd ls -la test.ibd.bz2 pbzip2 -d test.ibd.bz2 done
Compression results
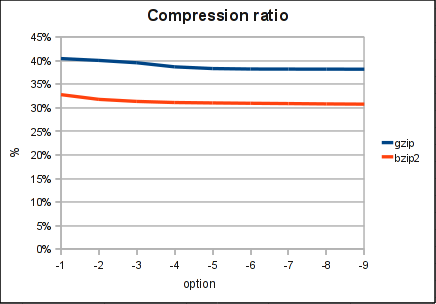
Compression Ratio
The compression ratio did not significantly increase in our tests. This is mostly dependent on the data which are compressed. Further tests have to be done here.
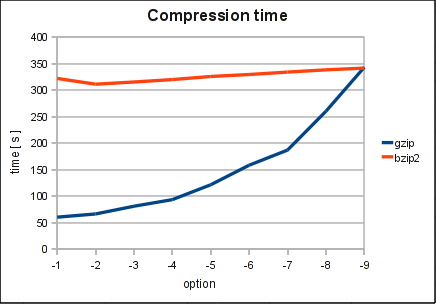
Compression Time
bzip2 seems to have more or less stable compression times. Where the compression time of gzip heavily depends on the compression option.
With gzip the default option is -6 and with bzip2 -9. The graphs show pretty well that those values are quite a good choice.
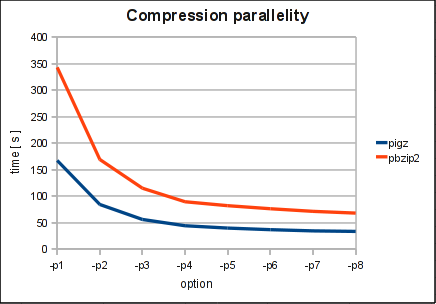
Compression Parallelity
An increase of parallelism up to the number of physical cores helps to reduces compression time significantly. Above this number there is only a very small gain.
Conclusion: Personally I was pretty impressed that the best compression mode with gzip was about 5.5 times slower than the fastest one. On the other hand the benefit in compression with gzip increased just from 40.5% to 38.2% (32.8% to 30.8% with bzip2). OK, it depends a bit on the data to compress but I think they are quite realistic. Typically we see compression rates of 5-7 for normal mysqldump files.
As a second result came out that parallelizing compression reduces the compression time a lot with the parallel compression tools. Up to the number of physical cores it seems to make sense to increase the degree of parallelism.
In short: I will not use gzip -9 anymore. -6 (the default) is typically more than enough. And with parallel gzip (pigz) in combination with the flag -1 you should gain up to 12 times faster compression times.
If you have results which are showing a different picture I would love to learn about!
A similar topic is InnoDB Block Compression which is new with MySQL 5.5 (5.1 with InnoDB Plugin).
- Shinguz's blog
- Log in or register to post comments
Comments
faster compression